publications
/* denotes equal contribution.
2026
- WACV
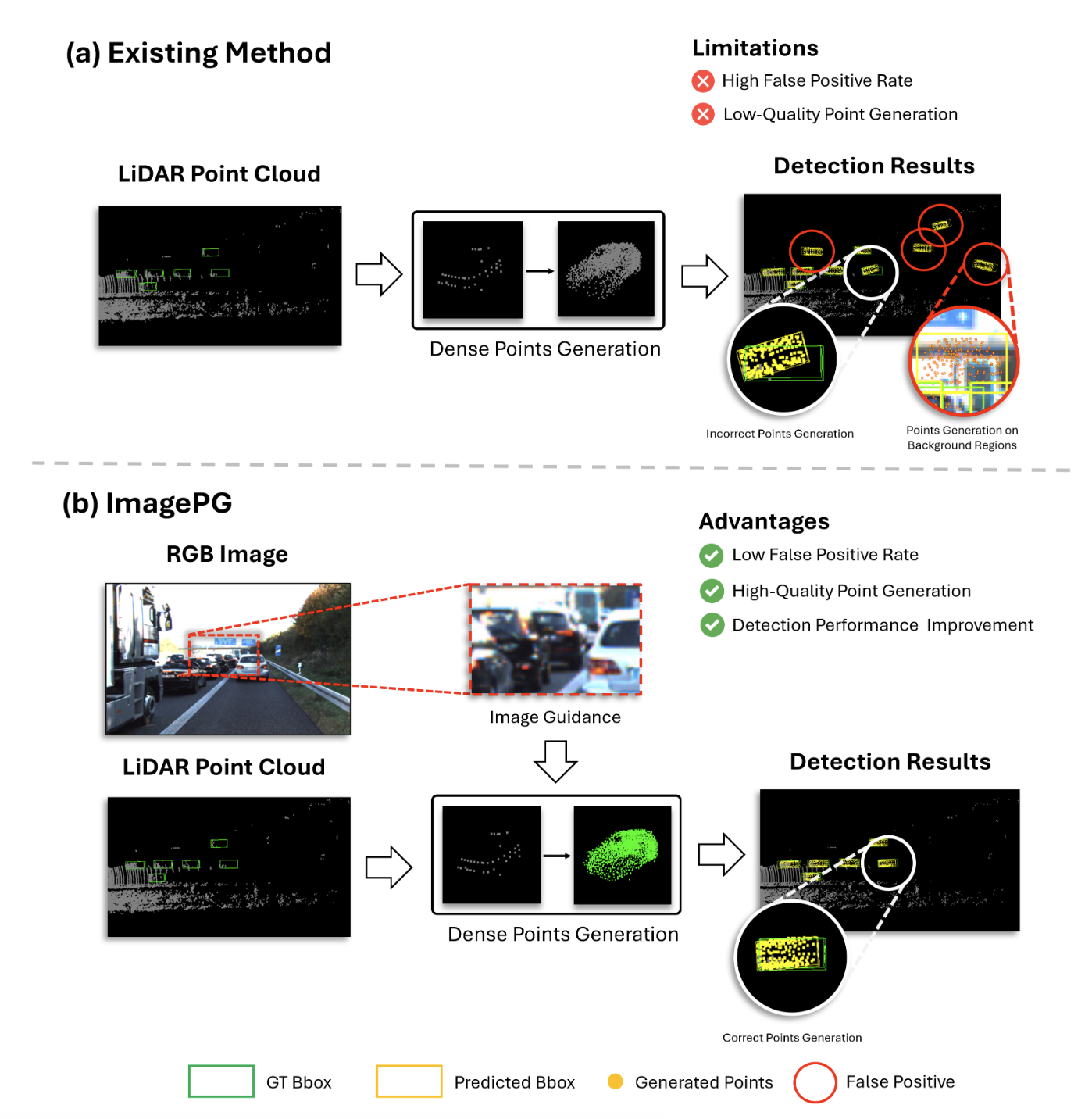 Image-Guided Semantic Pseudo-LiDAR Point Generation for 3D Object DetectionMinseung Lee, Seokha Moon, Reza Mahjourian, and Jinkyu KimWinter Conference on Applications of Computer Vision (WACV), 2026
Image-Guided Semantic Pseudo-LiDAR Point Generation for 3D Object DetectionMinseung Lee, Seokha Moon, Reza Mahjourian, and Jinkyu KimWinter Conference on Applications of Computer Vision (WACV), 2026In autonomous driving scenarios, accurate perception is becoming an even more critical task for safe navigation. While LiDAR provides precise spatial data, its inherent sparsity makes it difficult to detect small or distant objects. Existing methods try to address this by generating additional points within a Region of Interest (RoI), but relying on LiDAR alone often leads to false positives and a failure to recover meaningful structures. To address these limitations, we propose Image-Guided Semantic Pseudo-LiDAR Point Generation model, called ImagePG, a novel framework that leverages rich RGB image features to generate dense and semantically meaningful 3D points. Our framework includes an Image-Guided RoI Points Generation (IG-RPG) module, which creates pseudo-points guided by image features, and an Image-Aware Occupancy Prediction Network (I-OPN), which provides spatial priors to guide point placement. A multi-stage refinement (MR) module further enhances point quality and detection robustness. To the best of our knowledge, ImagePG is the first method to directly leverage image features for point generation. Extensive experiments on the KITTI and Waymo datasets demonstrate that ImagePG significantly improves the detection of small and distant objects like pedestrians and cyclists, reducing false positives by nearly 50%. On the KITTI benchmark, our framework improves mAP by +1.38%p (car), +7.91%p (pedestrian), and +5.21%p (cyclist) on the test set over the baseline, achieving state-of-the-art cyclist performance on the KITTI leaderboard.
2025
- Preprint
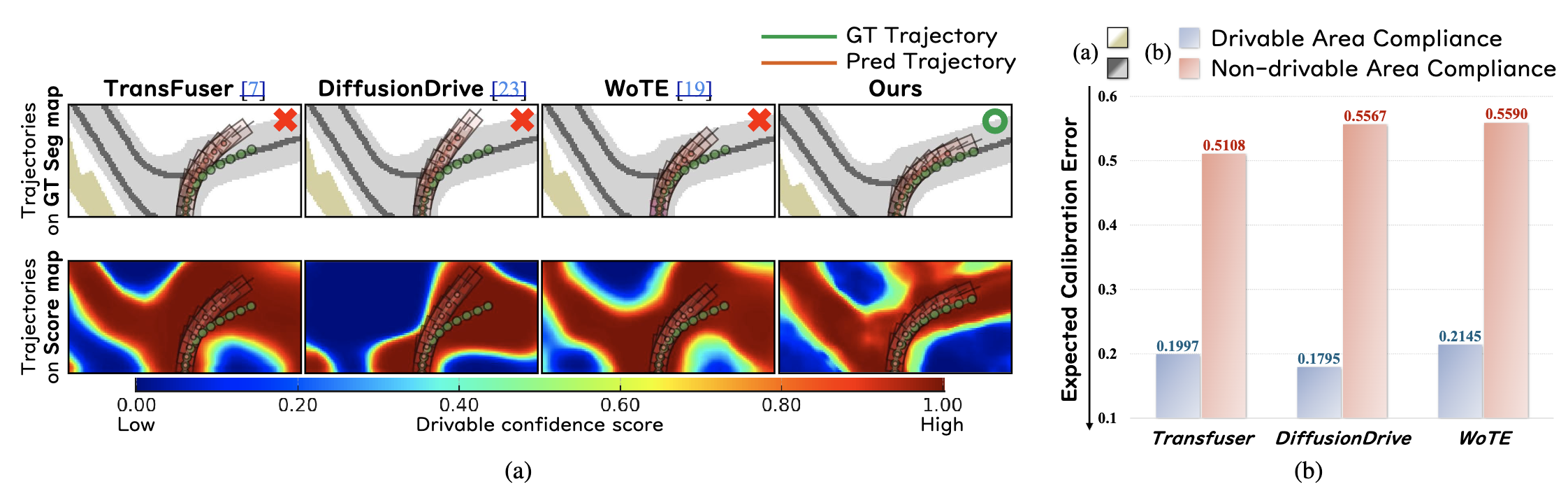 SUPER-AD: Semantic Uncertainty-aware Planning for End-to-End Robust Autonomous DrivingWonjeong Ryu, Seungjun Yu, Seokha Moon, Hojun Choi, Junsung Park, Jinkyu Kim, and Hyunjung ShimArxiv Preprint, 2025
SUPER-AD: Semantic Uncertainty-aware Planning for End-to-End Robust Autonomous DrivingWonjeong Ryu, Seungjun Yu, Seokha Moon, Hojun Choi, Junsung Park, Jinkyu Kim, and Hyunjung ShimArxiv Preprint, 2025End-to-End (E2E) planning has become a powerful paradigm for autonomous driving, yet current systems remain fundamentally uncertainty-blind. They assume perception outputs are fully reliable, even in ambiguous or poorly observed scenes, leaving the planner without an explicit measure of uncertainty. To address this limitation, we propose a camera-only E2E framework that estimates aleatoric uncertainty directly in BEV space and incorporates it into planning. Our method produces a dense, uncertainty-aware drivability map that captures both semantic structure and geometric layout at pixel-level resolution. To further promote safe and rule-compliant behavior, we introduce a lane-following regularization that encodes lane structure and traffic norms. This prior stabilizes trajectory planning under normal conditions while preserving the flexibility needed for maneuvers such as overtaking or lane changes. Together, these components enable robust and interpretable trajectory planning, even under challenging uncertainty conditions. Evaluated on the NAVSIM benchmark, our method achieves state-of-the-art performance, delivering substantial gains on both the challenging NAVHARD and NAVSAFE subsets. These results demonstrate that our principled aleatoric uncertainty modeling combined with driving priors significantly advances the safety and reliability of camera-only E2E autonomous driving.
- Preprint
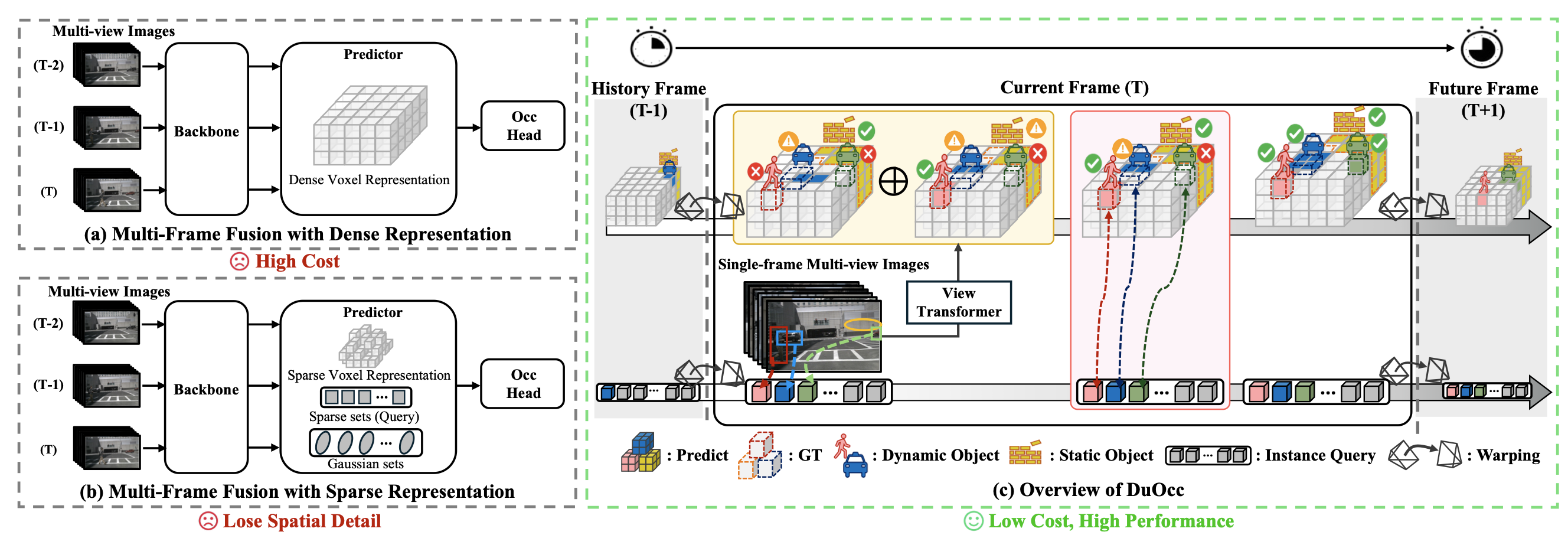 Stream and Query-guided Feature Aggregation for Efficient and Effective 3D Occupancy PredictionSeokha Moon, Janghyun Baek, Giseop Kim, Jinkyu Kim, and Sunwook ChoiArxiv Preprint, 2025
Stream and Query-guided Feature Aggregation for Efficient and Effective 3D Occupancy PredictionSeokha Moon, Janghyun Baek, Giseop Kim, Jinkyu Kim, and Sunwook ChoiArxiv Preprint, 20253D occupancy prediction has become a key perception task in autonomous driving, as it enables comprehensive scene understanding. Recent methods enhance this understanding by incorporating spatiotemporal information through multi-frame fusion, but they suffer from a trade-off: dense voxel-based representations provide high accuracy at significant computational cost, whereas sparse representations improve efficiency but lose spatial detail. To mitigate this trade-off, we introduce DuOcc, which employs a dual aggregation strategy that retains dense voxel representations to preserve spatial fidelity while maintaining high efficiency. DuOcc consists of two key components: (i) Stream-based Voxel Aggregation, which recurrently accumulates voxel features over time and refines them to suppress warping-induced distortions, preserving a clear separation between occupied and free space. (ii) Query-guided Aggregation, which complements the limitations of voxel accumulation by selectively injecting instance-level query features into the voxel regions occupied by dynamic objects. Experiments on the widely used Occ3D-nuScenes and SurroundOcc datasets demonstrate that DuOcc achieves state-of-the-art performance in real-time settings, while reducing memory usage by over 40% compared to prior methods.
2024
- ECCV
 VisionTrap: Vision-Augmented Trajectory Prediction Guided by Textual DescriptionsSeokha Moon, Hyun Woo, Hongbeen Park, Haeji Jung, Reza Mahjourian, Hyung-gun Chi, Hyerin Lim, Sangpil Kim, and Jinkyu KimEuropean Conference on Computer Vision (ECCV), 2024
VisionTrap: Vision-Augmented Trajectory Prediction Guided by Textual DescriptionsSeokha Moon, Hyun Woo, Hongbeen Park, Haeji Jung, Reza Mahjourian, Hyung-gun Chi, Hyerin Lim, Sangpil Kim, and Jinkyu KimEuropean Conference on Computer Vision (ECCV), 2024Predicting future trajectories for other road agents is an essential task for autonomous vehicles. Established trajectory prediction methods primarily use agent tracks generated by a detection and tracking system and HD map as inputs. In this work, we propose a novel method that also incorporates visual input from surround-view cameras, allowing the model to utilize visual cues such as human gazes and gestures, road conditions, vehicle turn signals, etc, which are typically hidden from the model in prior methods. Furthermore, we use textual descriptions generated by a Vision-Language Model (VLM) and refined by a Large Language Model (LLM) as supervision during training to guide the model on what to learn from the input data. Despite using these extra inputs, our method achieves a latency of 53 ms, making it feasible for real-time processing, which is significantly faster than that of previous single-agent prediction methods with similar performance. Our experiments show that both the visual inputs and the textual descriptions contribute to improvements in trajectory prediction performance, and our qualitative analysis highlights how the model is able to exploit these additional inputs. Lastly, in this work we create and release the nuScenes-Text dataset, which augments the established nuScenes dataset with rich textual annotations for every scene, demonstrating the positive impact of utilizing VLM on trajectory prediction. Our project page is at here(https://moonseokha.github.io/VisionTrap)
- ICPR
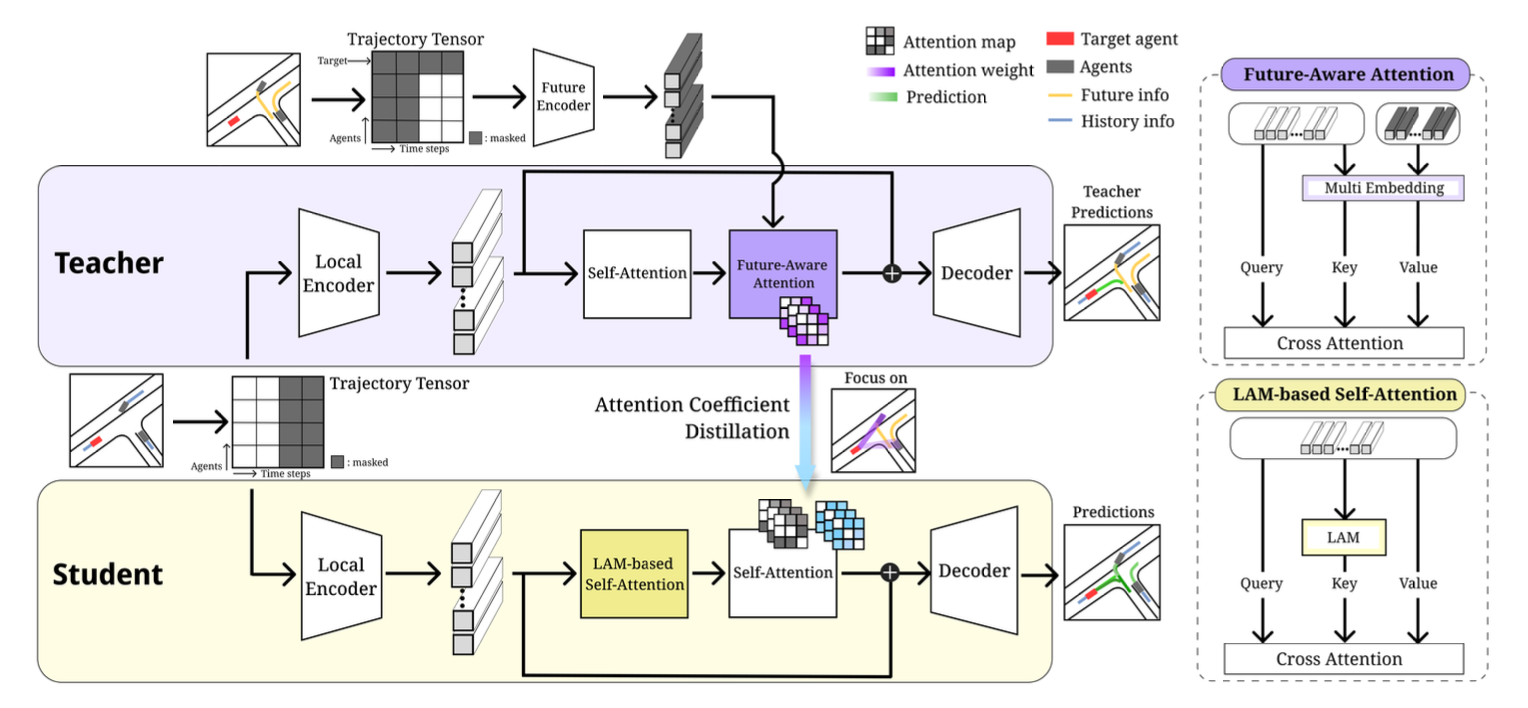 Who Should Have Been Focused: Transferring Attention-based Knowledge from Future Observations for Trajectory PredictionSeokha Moon, Kyuhwan Yeon, Hayoung Kim, Seong-Gyun Jeong, and Jinkyu KimInternational Conference on Pattern Recognition (ICPR), 2024
Who Should Have Been Focused: Transferring Attention-based Knowledge from Future Observations for Trajectory PredictionSeokha Moon, Kyuhwan Yeon, Hayoung Kim, Seong-Gyun Jeong, and Jinkyu KimInternational Conference on Pattern Recognition (ICPR), 2024Accurately predicting the future behaviors of dynamic agents is crucial for the safe navigation of autonomous robotics. However, it remains challenging because the agent’s intentions (or goals) are inherently uncertain, making it difficult to accurately predict their future poses given the past and current observations. To reduce such agents’ intentional uncertainties, we utilize a student-teacher learning approach where the teacher model leverages other agents’ ground-truth future observations to know which agents should be attended to for the final verdict. Such attentional knowledge is then transferred into the student model by forcing it to mimic the teacher model’s agent-wise attention. Further, we propose a Lane-guided Attention Module (LAM) to refine predicted trajectories with local information, bridging the information gap between the teacher and student models. We demonstrate the effectiveness of our proposed model with a large-scale Argoverse motion forecasting dataset, achieving matched or better performance than the current state-of-the-art approaches. Plus, our model generates more human-intuitive trajectories, e.g., avoiding collisions with other agents, keeping its lane, or considering relations with other agents.
- ICRA
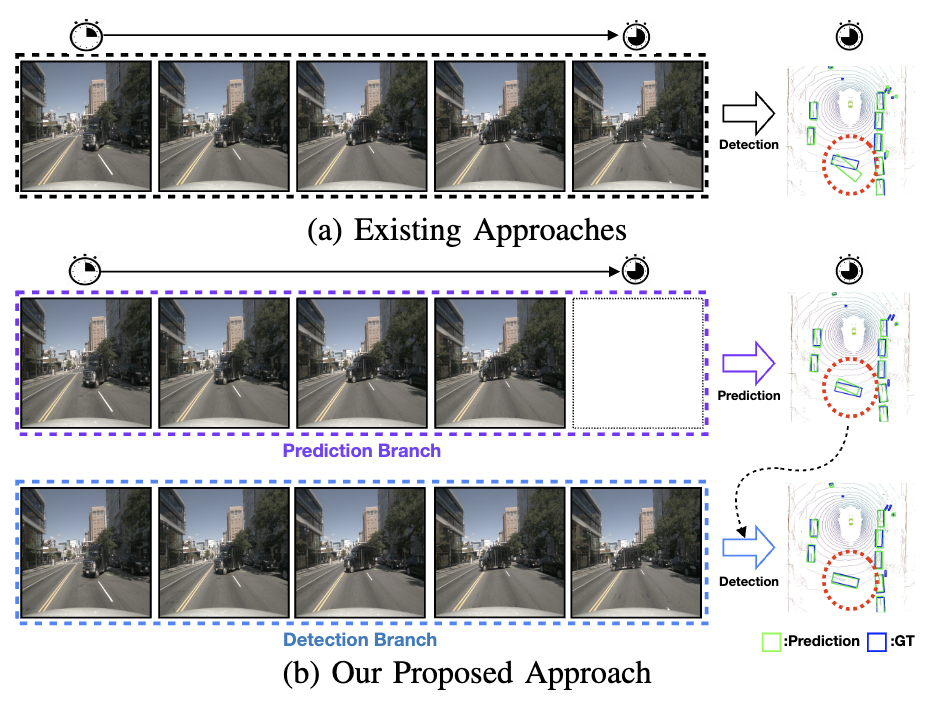 Learning Temporal Cues by Predicting Objects Move for Multi-camera 3D Object DetectionSeokha Moon, Hongbeen Park, Jungphil Kwon, Jaekoo Lee, and Jinkyu KimInternational Conference on Robotics and Automation (ICRA), 2024
Learning Temporal Cues by Predicting Objects Move for Multi-camera 3D Object DetectionSeokha Moon, Hongbeen Park, Jungphil Kwon, Jaekoo Lee, and Jinkyu KimInternational Conference on Robotics and Automation (ICRA), 2024In autonomous driving and robotics, there is a growing interest in utilizing short-term historical data to enhance multi-camera 3D object detection, leveraging the continuous and correlated nature of input video streams. Recent work has focused on spatially aligning BEV-based features over timesteps. However, this is often limited as its gain does not scale well with long-term past observations. To address this, we advocate for supervising a model to predict objects’ poses given past observations, thus explicitly guiding to learn objects’ temporal cues. To this end, we propose a model called DAP (Detection After Prediction), consisting of a two-branch network: (i) a branch responsible for forecasting the current objects’ poses given past observations and (ii) another branch that detects objects based on the current and past observations. The features predicting the current objects from branch (i) is fused into branch (ii) to transfer predictive knowledge. We conduct extensive experiments with the large-scale nuScenes datasets, and we observe that utilizing such predictive information significantly improves the overall detection performance. Our model can be used plug-and-play, showing consistent performance gain.
- WACV
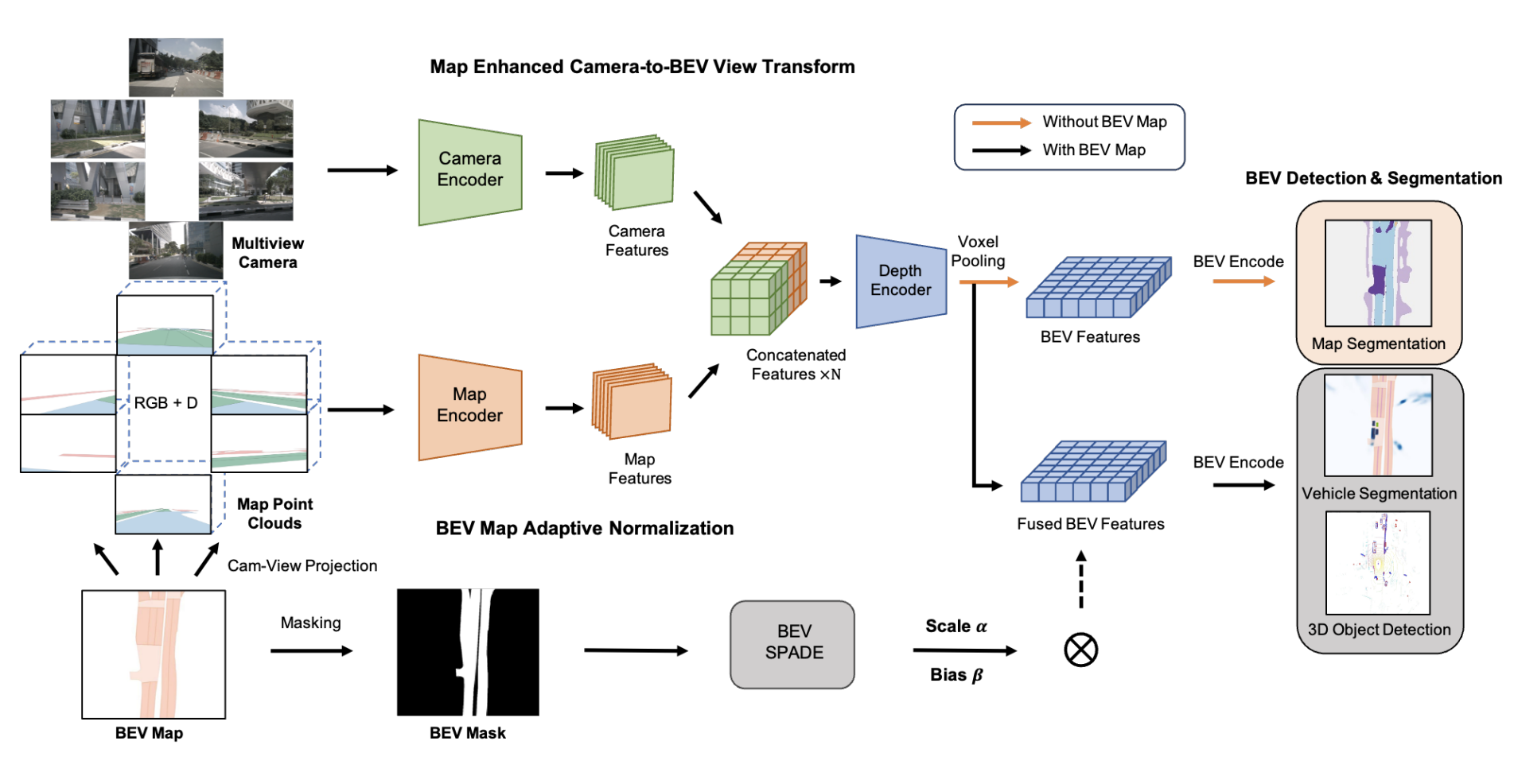 BEVMap: Map-Aware BEV Modeling for 3D PerceptionMincheol Chang, Seokha Moon, Reza Mahjourian, and Jinkyu KimWinter Conference on Applications of Computer Vision (WACV), 2024
BEVMap: Map-Aware BEV Modeling for 3D PerceptionMincheol Chang, Seokha Moon, Reza Mahjourian, and Jinkyu KimWinter Conference on Applications of Computer Vision (WACV), 2024In autonomous driving applications, there is a strong preference for modeling the world in Bird’s-Eye View (BEV), as it leads to improved accuracy and performance. BEV features are widely used in perception tasks since they allow fusing information from multiple views in an efficient manner. However, BEV features generated from camera images are prone to be imprecise due to the difficulty of estimating depth in the perspective view. Improper placement of BEV features limits the accuracy of downstream tasks. We introduce a method for incorporating map information to improve perspective depth estimation from 2D camera images and thereby producing geometrically- and semantically-robust BEV features. We show that augmenting the camera images with the BEV map and map-to-camera projections can compensate for the depth uncertainty and enrich camera-only BEV features with road contexts. Experiments on the nuScenes dataset demonstrate that our method outperforms previous approaches using only camera images in segmentation and detection tasks.
2023
- CVPRW
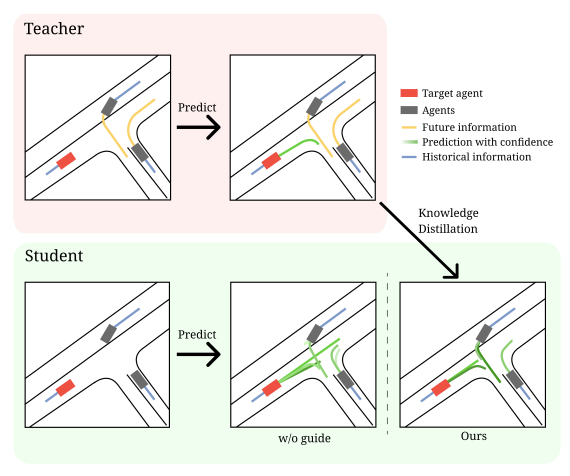 RUFI: Reducing Uncertainty in behavior prediction with Future InformationSeokha Moon, Sejeong Lee, Hyun Woo, Kyuhwan Yeon, Hayoung Kim, Seong-Gyun Jeong, and Jinkyu KimCVPR Workshop on Vision-Centric Autonomous Driving (VCAD), 2023
RUFI: Reducing Uncertainty in behavior prediction with Future InformationSeokha Moon, Sejeong Lee, Hyun Woo, Kyuhwan Yeon, Hayoung Kim, Seong-Gyun Jeong, and Jinkyu KimCVPR Workshop on Vision-Centric Autonomous Driving (VCAD), 2023
2022
- BMVC
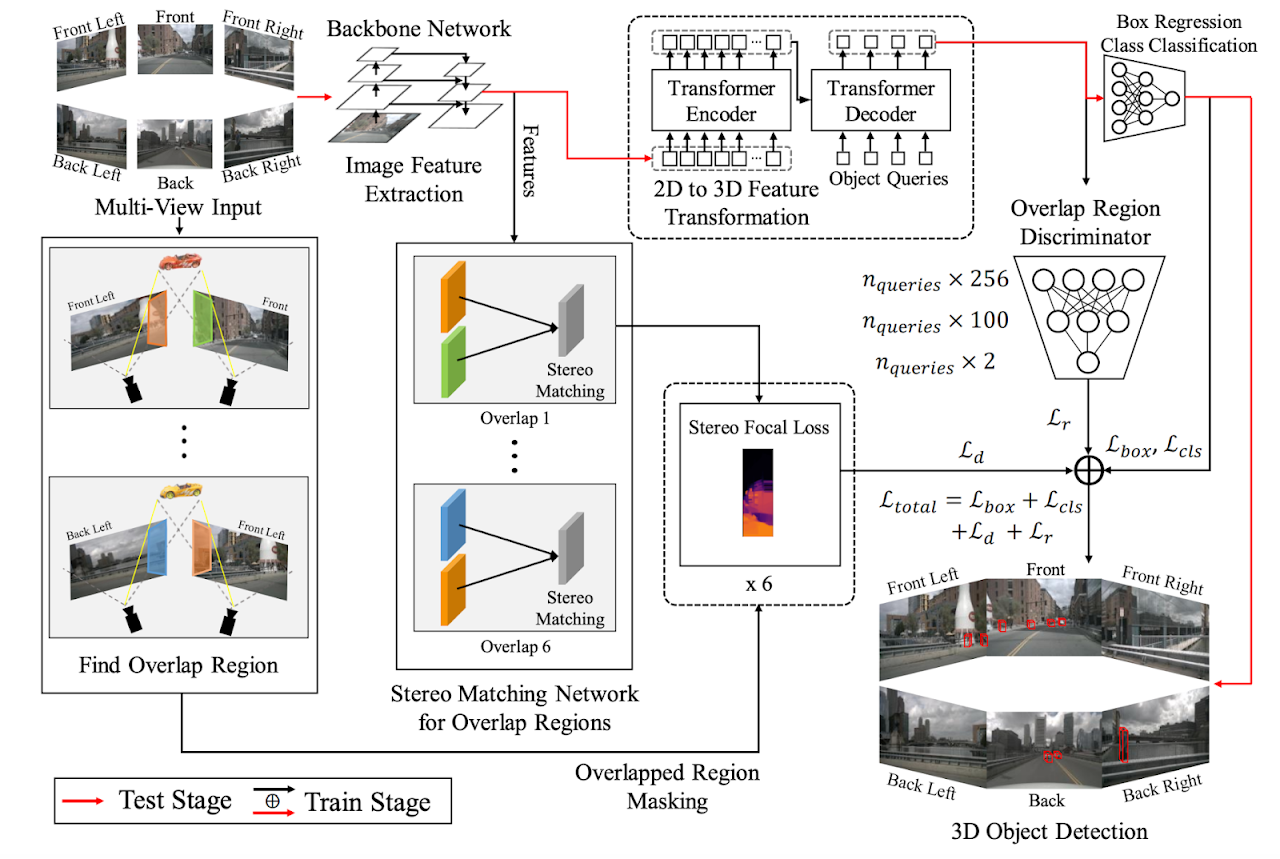 ORA3D: Overlap Region Aware Multi-view 3D Object DetectionWonseok Roh, Gyusam Chang, Seokha Moon, Giljoo Nam, Chanyoung Kim, Younghyun Kim, Jinkyu Kim, and Sangpil KimBritish Machine Vision Conference (BMVC), 2022
ORA3D: Overlap Region Aware Multi-view 3D Object DetectionWonseok Roh, Gyusam Chang, Seokha Moon, Giljoo Nam, Chanyoung Kim, Younghyun Kim, Jinkyu Kim, and Sangpil KimBritish Machine Vision Conference (BMVC), 2022Current multi-view 3D object detection methods often fail to detect objects in the overlap region properly, and the networks’ understanding of the scene is often limited to that of a monocular detection network. Moreover, objects in the overlap region are often largely occluded or suffer from deformation due to camera distortion, causing a domain shift. To mitigate this issue, we propose using the following two main modules: (1) Stereo Disparity Estimation for Weak Depth Supervision and (2) Adversarial Overlap Region Discriminator. The former utilizes the traditional stereo disparity estimation method to obtain reliable disparity information from the overlap region. Given the disparity estimates as supervision, we propose regularizing the network to fully utilize the geometric potential of binocular images and improve the overall detection accuracy accordingly. Further, the latter module minimizes the representational gap between non-overlap and overlapping regions. We demonstrate the effectiveness of the proposed method with the nuScenes large-scale multi-view 3D object detection data. Our experiments show that our proposed method outperforms current state-of-the-art models, i.e., DETR3D and BEVDet.